
 Python初心者
Python初心者Pythonの入門レベルの人向けにKaggleの解答解説とかないかなぁ
こんな悩みを持っている方向けにKaggleで扱っている問題の解答解説をまとめていきたいと思います。
なお本記事で対象としているのは、House Prices – Advanced Regression Techniques | Kaggleというもので、「住宅価格の予測」をする問題です。
データサイエンスをどのような考え方で進めていけばよいのかを、可能な限りわかりやすくまとめていきたいと思います。
なお本記事は、Kaggleへのアカウント登録が完了し、データの加工や出力を行うPythonのライブラリ(Pandas, Matplotlib等)を理解している前提でまとめていきたいと思います。
\ 無料オンライン説明会受付中! /
【Python】Kaggleのnotebookでデータを取得する
Kaggleのnotebookを新規作成すると、以下のコードが既に用意されていると思うので、これを実行しましょう。
コードは、「shift + Enter」か「option + Enter」で実行できます。
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
## 実行結果
# /kaggle/input/house-prices-advanced-regression-techniques/sample_submission.csv
# /kaggle/input/house-prices-advanced-regression-techniques/data_description.txt
# /kaggle/input/house-prices-advanced-regression-techniques/train.csv
# /kaggle/input/house-prices-advanced-regression-techniques/test.csv実行結果を見ると、4つのファイルが存在することが確認できます。
まず/kaggle/input/house-prices-advanced-regression-techniques/train.csvというファイルは、「訓練データ」です。
そして/kaggle/input/house-prices-advanced-regression-techniques/test.csvというファイルが「テストデータ」です。
/kaggle/input/house-prices-advanced-regression-techniques/sample_submission.csvは、Kaggleに最終的な予測値を提出するファイルのサンプルです。
/kaggle/input/house-prices-advanced-regression-techniques/data_description.txtは、Kaggleで用意したデータの説明が記載されているファイルです。
なおKaggleで用意されているファイルは、House Prices – Advanced Regression Techniques | Kaggle からブラウザ上で確認できます。
コンペティションに参加する際は、用意されているデータから「データの数」、「データの型」、「最終的に提出するデータの様式」あたりを確認しておきましょう。
続いて必要とされるライブラリをimportしていきます。
import sklearn
import pandas
import numpy
import matplotlib
import sklearn次にKaggleで用意されているデータを取得します。データの取得はpandasを用いて以下のコードを実行すればOKです。データの読み込みや出力する際のpandasの使い方は、【解説】データサイエンス100本ノック【問94〜100回答】 – omathin blogを参考にしていただけたらと思います。
# 訓練データの読み込み
train_df = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/train.csv')
# テストデータの読み込み
test_df = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/test.csv')これで、訓練データとテストデータを読み込むことができました。
【Python】Kaggleで用意されているデータを確認する
住宅価格の予測を行うために使用するデータを確認していきます。
確認する観点は以下です。
データを確認する主な観点(5つ)
- どのような変数(特徴量)が存在するのか
- データの型は何か
- データに欠損値は存在するのか
- データに重複が存在するのか
- データ間に相関があるのか
なぜデータを確認する必要があるのかというと、データを活用して物事を分類したり予測するためには、もととなるデータの品質が肝となるからです。データに欠損値が存在したり、機械では読み取れない文字列データが含まれていると、肝心のデータを活用して分析をすることができません。
まずは用意されているデータを理解し、データにどのような加工や補完が必要なのか計画を立てましょう。
それでは一つずつ確認していきます。
データの特徴量の確認
データの特徴量の確認は、主に「カラム名」「各カラムのデータの意味」を大まかに確認します。
Kaggleの場合、ポータル上でデータの特徴量と各カラムのデータの意味を確認することができます。
https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data
上記のリンクを押し、「Data Explorer」という項目から、確認したいデータを選択することで、各データの内容を確認できます。以下の画像は、data_description.txtファイルを確認している様子です。
更に以下のコードを実行することで、カラム名を一括で出力することが可能です。
train_df.columns.values
# array(['Id', 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street',
# 'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig',
# 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2',
# 'BldgType', 'HouseStyle', 'OverallQual', 'OverallCond',
# 'YearBuilt', 'YearRemodAdd', 'RoofStyle', 'RoofMatl',
# 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea',
# 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond',
# 'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1', 'BsmtFinType2',
# 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating', 'HeatingQC',
# 'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF',
# 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath',
# 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual',
# 'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu',
# 'GarageType', 'GarageYrBlt', 'GarageFinish', 'GarageCars',
# 'GarageArea', 'GarageQual', 'GarageCond', 'PavedDrive',
# 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch',
# 'ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature',
# 'MiscVal', 'MoSold', 'YrSold', 'SaleType', 'SaleCondition',
# 'SalePrice'], dtype=object)このあたりは大まかな理解で問題ありません。データ全体の構造がどうなっていて、どのくらいのカラム数なのかを把握しておけば良いでしょう。
データの型を確認する
データの型は.info()メソッドを活用することで一括で確認できます。
train_df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 1460 entries, 0 to 1459
# Data columns (total 81 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Id 1460 non-null int64
# 1 MSSubClass 1460 non-null int64
# 2 MSZoning 1460 non-null object
# 3 LotFrontage 1201 non-null float64
# 4 LotArea 1460 non-null int64
# 5 Street 1460 non-null object
# 6 Alley 91 non-null object
# 7 LotShape 1460 non-null object
# 8 LandContour 1460 non-null object
# 9 Utilities 1460 non-null object
# 10 LotConfig 1460 non-null object
# 11 LandSlope 1460 non-null object
# 12 Neighborhood 1460 non-null object
# 13 Condition1 1460 non-null object
# 14 Condition2 1460 non-null object
# 15 BldgType 1460 non-null object
# 16 HouseStyle 1460 non-null object
# 17 OverallQual 1460 non-null int64
# 18 OverallCond 1460 non-null int64
# 19 YearBuilt 1460 non-null int64
# 20 YearRemodAdd 1460 non-null int64
# 21 RoofStyle 1460 non-null object
# 22 RoofMatl 1460 non-null object
# 23 Exterior1st 1460 non-null object
# 24 Exterior2nd 1460 non-null object
# 25 MasVnrType 1452 non-null object
# 26 MasVnrArea 1452 non-null float64
# 27 ExterQual 1460 non-null object
# 28 ExterCond 1460 non-null object
# 29 Foundation 1460 non-null object
# 30 BsmtQual 1423 non-null object
# 31 BsmtCond 1423 non-null object
# 32 BsmtExposure 1422 non-null object
# 33 BsmtFinType1 1423 non-null object
# 34 BsmtFinSF1 1460 non-null int64
# 35 BsmtFinType2 1422 non-null object
# 36 BsmtFinSF2 1460 non-null int64
# 37 BsmtUnfSF 1460 non-null int64
# 38 TotalBsmtSF 1460 non-null int64
# 39 Heating 1460 non-null object
# 40 HeatingQC 1460 non-null object
# 41 CentralAir 1460 non-null object
# 42 Electrical 1459 non-null object
# 43 1stFlrSF 1460 non-null int64
# 44 2ndFlrSF 1460 non-null int64
# 45 LowQualFinSF 1460 non-null int64
# 46 GrLivArea 1460 non-null int64
# 47 BsmtFullBath 1460 non-null int64
# 48 BsmtHalfBath 1460 non-null int64
# 49 FullBath 1460 non-null int64
# 50 HalfBath 1460 non-null int64
# 51 BedroomAbvGr 1460 non-null int64
# 52 KitchenAbvGr 1460 non-null int64
# 53 KitchenQual 1460 non-null object
# 54 TotRmsAbvGrd 1460 non-null int64
# 55 Functional 1460 non-null object
# 56 Fireplaces 1460 non-null int64
# 57 FireplaceQu 770 non-null object
# 58 GarageType 1379 non-null object
# 59 GarageYrBlt 1379 non-null float64
# 60 GarageFinish 1379 non-null object
# 61 GarageCars 1460 non-null int64
# 62 GarageArea 1460 non-null int64
# 63 GarageQual 1379 non-null object
# 64 GarageCond 1379 non-null object
# 65 PavedDrive 1460 non-null object
# 66 WoodDeckSF 1460 non-null int64
# 67 OpenPorchSF 1460 non-null int64
# 68 EnclosedPorch 1460 non-null int64
# 69 3SsnPorch 1460 non-null int64
# 70 ScreenPorch 1460 non-null int64
# 71 PoolArea 1460 non-null int64
# 72 PoolQC 7 non-null object
# 73 Fence 281 non-null object
# 74 MiscFeature 54 non-null object
# 75 MiscVal 1460 non-null int64
# 76 MoSold 1460 non-null int64
# 77 YrSold 1460 non-null int64
# 78 SaleType 1460 non-null object
# 79 SaleCondition 1460 non-null object
# 80 SalePrice 1460 non-null int64
# dtypes: float64(3), int64(35), object(43)
# memory usage: 924.0+ KB同様にtest_df.info()も確認しておきましょう。
出力結果のDtypeという列を確認しましょう。int64そしてfloat64となっているカラムは、数値データです。
そしてobjectとなっているデータが、主に文字列のデータになります。
objectデータに関しては、コンピュータが読み取れるように数値データに変換する処理(エンコーディング)をする必要があるということだけここでは認識しておきましょう。
データサイエンスに慣れてくるとこの段階でそれぞれのobjectデータに対してどのような処理を行うのかの目星が着けられます。この記事を読み終えれば、どういうことなのかが分かると思うので頑張りましょう。
データの欠損値を確認する
各特徴量には欠損値が含まれている可能性があります。
ここでは欠損値を確認していきます。
欠損値を算出するにはisnullメソッドとsumメソッドを使用します。
pd.set_option('display.max_rows', 500)
train_df.isnull().sum()
Id 0
# MSSubClass 0
# MSZoning 0
# LotFrontage 259
# LotArea 0
# Street 0
# Alley 1369
# ///省略///
# PoolQC 1453
# Fence 1179
# MiscFeature 1406
# MiscVal 0
# MoSold 0
# YrSold 0
# SaleType 0
# SaleCondition 0
# SalePrice 0
# dtype: int64出力された数値が、欠損値の数になります。
このことから、各データの意味や性質を踏まえて欠損値を補完する処理がどの程度必要なのかを把握することができます。
同様にtest_dfについても欠損値の有無を確認しておきましょう。
データの重複を確認する
データが重複しているかも確認していきます。
重複を確認するには、describeメソッドを利用します。
train_df.describe(include=['O'])
# MSZoning Street Alley LotShape LandContour Utilities LotConfig LandSlope Neighborhood Condition1 ... GarageType GarageFinish GarageQual GarageCond PavedDrive PoolQC Fence MiscFeature SaleType SaleCondition
# count 1460 1460 91 1460 1460 1460 1460 1460 1460 1460 ... 1379 1379 1379 1379 1460 7 281 54 1460 1460
# unique 5 2 2 4 4 2 5 3 25 9 ... 6 3 5 5 3 3 4 4 9 6
# top RL Pave Grvl Reg Lvl AllPub Inside Gtl NAmes Norm ... Attchd Unf TA TA Y Gd MnPrv Shed WD Normal
# freq 1151 1454 50 925 1311 1459 1052 1382 225 1260 ... 870 605 1311 1326 1340 3 157 49 1267 1198
countはデータの個数(件数)です
uniqueは、重複を排除したデータの個数です。
topは、最も多く含まれる値です。
freqは最も多く含まれる値(top)が含まれる個数です。
ここからは特に読み取れる情報はなさそうです。
データの相関を確認する
数ある特徴量の中から相関を見つけ出すための手段として、seabornを用いて確認する方法があります。
視覚的に特徴量同士の相関を把握したい場合は、ペアプロット図(散布図行列)を出力するか、ヒートマップを出力するやり方があります。
ここではヒートマップを実施します。
import seaborn as sns
sns.heatmap(train_df.corr(), square=True)
今回の場合、正の相関がある場合は白く表示され、無相関だと黒く表示されます。
相関とはなにかについては、別記事で改めてまとめようと思います。
今回の場合、最終的に予測をするSalesPriceとの相関を細かく見ていきたいので、corrメソッドを用いて数値的に相関を確認していきます。
またSalesPriceとの相関の強さ(相関係数)を降順にソートさせたいと思います。
corr = train_df.corr()
corr.sort_values('SalePrice', ascending=False)
# Id MSSubClass LotFrontage LotArea OverallQual OverallCond YearBuilt YearRemodAdd MasVnrArea BsmtFinSF1 ... WoodDeckSF OpenPorchSF EnclosedPorch 3SsnPorch ScreenPorch PoolArea MiscVal MoSold YrSold SalePrice
# SalePrice -0.021917 -0.084284 0.351799 0.263843 0.790982 -0.077856 0.522897 0.507101 0.477493 0.386420 ... 0.324413 0.315856 -0.128578 0.044584 0.111447 0.092404 -0.021190 0.046432 -0.028923 1.000000
# OverallQual -0.028365 0.032628 0.251646 0.105806 1.000000 -0.091932 0.572323 0.550684 0.411876 0.239666 ... 0.238923 0.308819 -0.113937 0.030371 0.064886 0.065166 -0.031406 0.070815 -0.027347 0.790982
# GrLivArea 0.008273 0.074853 0.402797 0.263116 0.593007 -0.079686 0.199010 0.287389 0.390857 0.208171 ... 0.247433 0.330224 0.009113 0.020643 0.101510 0.170205 -0.002416 0.050240 -0.036526 0.708624
# GarageCars 0.016570 -0.040110 0.285691 0.154871 0.600671 -0.185758 0.537850 0.420622 0.364204 0.224054 ... 0.226342 0.213569 -0.151434 0.035765 0.050494 0.020934 -0.043080 0.040522 -0.039117 0.640409
# GarageArea 0.017634 -0.098672 0.344997 0.180403 0.562022 -0.151521 0.478954 0.371600 0.373066 0.296970 ... 0.224666 0.241435 -0.121777 0.035087 0.051412 0.061047 -0.027400 0.027974 -0.027378 0.623431
# TotalBsmtSF -0.015415 -0.238518 0.392075 0.260833 0.537808 -0.171098 0.391452 0.291066 0.363936 0.522396 ... 0.232019 0.247264 -0.095478 0.037384 0.084489 0.126053 -0.018479 0.013196 -0.014969 0.613581
# 1stFlrSF 0.010496 -0.251758 0.457181 0.299475 0.476224 -0.144203 0.281986 0.240379 0.344501 0.445863 ... 0.235459 0.211671 -0.065292 0.056104 0.088758 0.131525 -0.021096 0.031372 -0.013604 0.605852
# FullBath 0.005587 0.131608 0.198769 0.126031 0.550600 -0.194149 0.468271 0.439046 0.276833 0.058543 ... 0.187703 0.259977 -0.115093 0.035353 -0.008106 0.049604 -0.014290 0.055872 -0.019669 0.560664
# TotRmsAbvGrd 0.027239 0.040380 0.352096 0.190015 0.427452 -0.057583 0.095589 0.191740 0.280682 0.044316 ... 0.165984 0.234192 0.004151 -0.006683 0.059383 0.083757 0.024763 0.036907 -0.034516 0.533723
# YearBuilt -0.012713 0.027850 0.123349 0.014228 0.572323 -0.375983 1.000000 0.592855 0.315707 0.249503 ... 0.224880 0.188686 -0.387268 0.031355 -0.050364 0.004950 -0.034383 0.012398 -0.013618 0.522897
# YearRemodAdd -0.021998 0.040581 0.088866 0.013788 0.550684 0.073741 0.592855 1.000000 0.179618 0.128451 ... 0.205726 0.226298 -0.193919 0.045286 -0.038740 0.005829 -0.010286 0.021490 0.035743 0.507101
# GarageYrBlt 0.000072 0.085072 0.070250 -0.024947 0.547766 -0.324297 0.825667 0.642277 0.252691 0.153484 ... 0.224577 0.228425 -0.297003 0.023544 -0.075418 -0.014501 -0.032417 0.005337 -0.001014 0.486362
# MasVnrArea -0.050298 0.022936 0.193458 0.104160 0.411876 -0.128101 0.315707 0.179618 1.000000 0.264736 ... 0.159718 0.125703 -0.110204 0.018796 0.061466 0.011723 -0.029815 -0.005965 -0.008201 0.477493
# Fireplaces -0.019772 -0.045569 0.266639 0.271364 0.396765 -0.023820 0.147716 0.112581 0.249070 0.260011 ... 0.200019 0.169405 -0.024822 0.011257 0.184530 0.095074 0.001409 0.046357 -0.024096 0.466929
# BsmtFinSF1 -0.005024 -0.069836 0.233633 0.214103 0.239666 -0.046231 0.249503 0.128451 0.264736 1.000000 ... 0.204306 0.111761 -0.102303 0.026451 0.062021 0.140491 0.003571 -0.015727 0.014359 0.386420
# LotFrontage -0.010601 -0.386347 1.000000 0.426095 0.251646 -0.059213 0.123349 0.088866 0.193458 0.233633 ... 0.088521 0.151972 0.010700 0.070029 0.041383 0.206167 0.003368 0.011200 0.007450 0.351799
# WoodDeckSF -0.029643 -0.012579 0.088521 0.171698 0.238923 -0.003334 0.224880 0.205726 0.159718 0.204306 ... 1.000000 0.058661 -0.125989 -0.032771 -0.074181 0.073378 -0.009551 0.021011 0.022270 0.324413
# 2ndFlrSF 0.005590 0.307886 0.080177 0.050986 0.295493 0.028942 0.010308 0.140024 0.174561 -0.137079 ... 0.092165 0.208026 0.061989 -0.024358 0.040606 0.081487 0.016197 0.035164 -0.028700 0.319334
# OpenPorchSF -0.000477 -0.006100 0.151972 0.084774 0.308819 -0.032589 0.188686 0.226298 0.125703 0.111761 ... 0.058661 1.000000 -0.093079 -0.005842 0.074304 0.060762 -0.018584 0.071255 -0.057619 0.315856
# HalfBath 0.006784 0.177354 0.053532 0.014259 0.273458 -0.060769 0.242656 0.183331 0.201444 0.004262 ... 0.108080 0.199740 -0.095317 -0.004972 0.072426 0.022381 0.001290 -0.009050 -0.010269 0.284108
# LotArea -0.033226 -0.139781 0.426095 1.000000 0.105806 -0.005636 0.014228 0.013788 0.104160 0.214103 ... 0.171698 0.084774 -0.018340 0.020423 0.043160 0.077672 0.038068 0.001205 -0.014261 0.263843
# BsmtFullBath 0.002289 0.003491 0.100949 0.158155 0.111098 -0.054942 0.187599 0.119470 0.085310 0.649212 ... 0.175315 0.067341 -0.049911 -0.000106 0.023148 0.067616 -0.023047 -0.025361 0.067049 0.227122
# BsmtUnfSF -0.007940 -0.140759 0.132644 -0.002618 0.308159 -0.136841 0.149040 0.181133 0.114442 -0.495251 ... -0.005316 0.129005 -0.002538 0.020764 -0.012579 -0.035092 -0.023837 0.034888 -0.041258 0.214479
# BedroomAbvGr 0.037719 -0.023438 0.263170 0.119690 0.101676 0.012980 -0.070651 -0.040581 0.102821 -0.107355 ... 0.046854 0.093810 0.041570 -0.024478 0.044300 0.070703 0.007767 0.046544 -0.036014 0.168213
# ScreenPorch 0.001330 -0.026030 0.041383 0.043160 0.064886 0.054811 -0.050364 -0.038740 0.061466 0.062021 ... -0.074181 0.074304 -0.082864 -0.031436 1.000000 0.051307 0.031946 0.023217 0.010694 0.111447
# PoolArea 0.057044 0.008283 0.206167 0.077672 0.065166 -0.001985 0.004950 0.005829 0.011723 0.140491 ... 0.073378 0.060762 0.054203 -0.007992 0.051307 1.000000 0.029669 -0.033737 -0.059689 0.092404
# MoSold 0.021172 -0.013585 0.011200 0.001205 0.070815 -0.003511 0.012398 0.021490 -0.005965 -0.015727 ... 0.021011 0.071255 -0.028887 0.029474 0.023217 -0.033737 -0.006495 1.000000 -0.145721 0.046432
# 3SsnPorch -0.046635 -0.043825 0.070029 0.020423 0.030371 0.025504 0.031355 0.045286 0.018796 0.026451 ... -0.032771 -0.005842 -0.037305 1.000000 -0.031436 -0.007992 0.000354 0.029474 0.018645 0.044584
# BsmtFinSF2 -0.005968 -0.065649 0.049900 0.111170 -0.059119 0.040229 -0.049107 -0.067759 -0.072319 -0.050117 ... 0.067898 0.003093 0.036543 -0.029993 0.088871 0.041709 0.004940 -0.015211 0.031706 -0.011378
# BsmtHalfBath -0.020155 -0.002333 -0.007234 0.048046 -0.040150 0.117821 -0.038162 -0.012337 0.026673 0.067418 ... 0.040161 -0.025324 -0.008555 0.035114 0.032121 0.020025 -0.007367 0.032873 -0.046524 -0.016844
# MiscVal -0.006242 -0.007683 0.003368 0.038068 -0.031406 0.068777 -0.034383 -0.010286 -0.029815 0.003571 ... -0.009551 -0.018584 0.018361 0.000354 0.031946 0.029669 1.000000 -0.006495 0.004906 -0.021190
# Id 1.000000 0.011156 -0.010601 -0.033226 -0.028365 0.012609 -0.012713 -0.021998 -0.050298 -0.005024 ... -0.029643 -0.000477 0.002889 -0.046635 0.001330 0.057044 -0.006242 0.021172 0.000712 -0.021917
# LowQualFinSF -0.044230 0.046474 0.038469 0.004779 -0.030429 0.025494 -0.183784 -0.062419 -0.069071 -0.064503 ... -0.025444 0.018251 0.061081 -0.004296 0.026799 0.062157 -0.003793 -0.022174 -0.028921 -0.025606
# YrSold 0.000712 -0.021407 0.007450 -0.014261 -0.027347 0.043950 -0.013618 0.035743 -0.008201 0.014359 ... 0.022270 -0.057619 -0.009916 0.018645 0.010694 -0.059689 0.004906 -0.145721 1.000000 -0.028923
# OverallCond 0.012609 -0.059316 -0.059213 -0.005636 -0.091932 1.000000 -0.375983 0.073741 -0.128101 -0.046231 ... -0.003334 -0.032589 0.070356 0.025504 0.054811 -0.001985 0.068777 -0.003511 0.043950 -0.077856
# MSSubClass 0.011156 1.000000 -0.386347 -0.139781 0.032628 -0.059316 0.027850 0.040581 0.022936 -0.069836 ... -0.012579 -0.006100 -0.012037 -0.043825 -0.026030 0.008283 -0.007683 -0.013585 -0.021407 -0.084284
# EnclosedPorch 0.002889 -0.012037 0.010700 -0.018340 -0.113937 0.070356 -0.387268 -0.193919 -0.110204 -0.102303 ... -0.125989 -0.093079 1.000000 -0.037305 -0.082864 0.054203 0.018361 -0.028887 -0.009916 -0.128578
# KitchenAbvGr 0.002951 0.281721 -0.006069 -0.017784 -0.183882 -0.087001 -0.174800 -0.149598 -0.037610 -0.081007 ... -0.090130 -0.070091 0.037312 -0.024600 -0.051613 -0.014525 0.062341 0.026589 0.031687 -0.135907得られた結果から、’OverallQual’, ‘GrLivArea’, ‘GarageCars’, ‘GarageArea’, ‘TotalBsmtSF’あたりが相関がありそうです。
‘OverallQual’, ‘GrLivArea’, ‘GarageCars’, ‘GarageArea’, ‘TotalBsmtSF’ と ‘SalesPrice’との相関を散布図を用いて視覚的に確認します。
pals = ['OverallQual', 'GrLivArea', 'GarageCars', 'GarageArea', 'TotalBsmtSF']
for pal in pals:
train_df.plot.scatter(x=pal, y='SalePrice')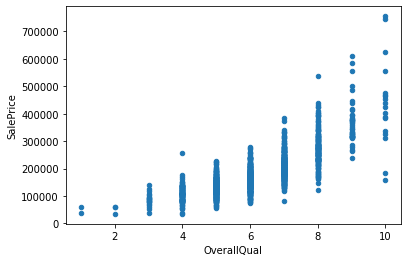
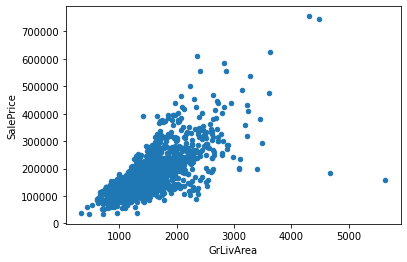
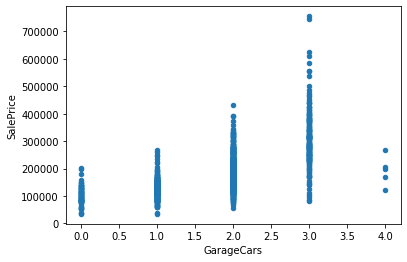
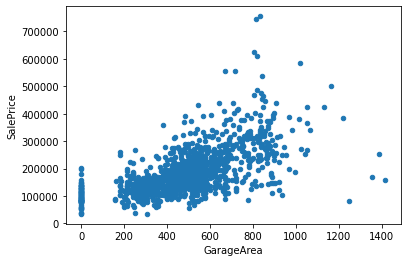
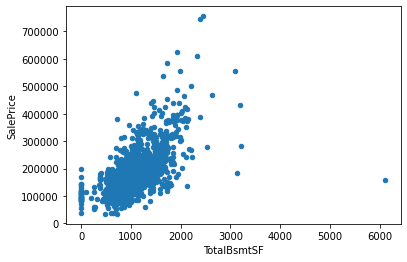
このことから、GrLivArea, GarageArea, TotalBsmtSFとSalesPriceの間に正の相関があることが見て取れます。
【Python】欠損値の補完
欠損値を補完するまえに、train_dfとtest_dfを連結させてcombined_dfという新しいデータフレーム(表形式のデータ)を作成します。なぜ連結させてcombined_dfを作成するのかというと、train_dfとtest_df両方に欠損値が存在し、それぞれに対して欠損値の補完を行う手間を省くためです。
以下の通りconcatを用いることで2つのデータフレームを連結させることができます。
combined_df = pd.concat((train_df, test_df))
combined_df.head(5)
# MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities ... PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice
# 0 1 60 RL 65.0 8450 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 2 2008 WD Normal 208500.0
# 1 2 20 RL 80.0 9600 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 5 2007 WD Normal 181500.0
# 2 3 60 RL 68.0 11250 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 9 2008 WD Normal 223500.0
# 3 4 70 RL 60.0 9550 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 2 2006 WD Abnorml 140000.0
# 4 5 60 RL 84.0 14260 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 12 2008 WD Normal 250000.0ここから欠損値の補完を進めていきます。
欠損値の補完は、各データの説明が記載されているdata_description.txtの内容から補完方針を決めた上で進めていきます。
欠損自体に意味を持っているobjectデータは”None”で補完する
「欠損自体に意味を持っている」というのはどういうことかを説明します。
例えば本コンペティションのデータの中にPoolQCという特徴量があります。
data_description.txtに記載されているPoolQCの欄には以下のように記述されています。
PoolQC: Pool quality NaN
411 NaN NaN
412 Ex Excellent
413 Gd Good
414 TA Average/Typical
415 Fa Fair
416 NA No PoolNAとなっているのがPoolQCにおける欠損値になります。この記述を見てみると、NA No Poolと記述されています。つまり、PoolQCにおける欠損値は、「”プールが存在しない”という意味を持っている」ということになります。
このように、データが欠損していることに意味を持っている場合は、"None"で補完を行う処理をしていきます。
欠損値を”None”で補完する処理はfillna()を使用します。
combined_df["PoolQC"] = combined_df["PoolQC"].fillna("None")なお、”MiscFeature”, “Alley”, “Fence”, “FireplaceQu”も同様にデータの欠損自体に意味を持っているため、"None"で補完します。
combined_df["MiscFeature"] = combined_df["MiscFeature"].fillna("None")
combined_df["Alley"] = combined_df["Alley"].fillna("None")
combined_df["Fence"] = combined_df["Fence"].fillna("None")
combined_df["FireplaceQu"] = combined_df["FireplaceQu"].fillna("None")上記のように一つ一つfillna()で処理しても良いですが、以下のようにfor文を用いて処理すると良いでしょう。GarageType, GarageFinish, GarageQual, GarageCond, も欠損値は「ガレージが無い」という意味を持っているので"None"で補完します。
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
combined_df[col] = combined_df[col].fillna('None')同様に地下室関連のデータである‘BsmtQual’, ‘BsmtCond’, ‘BsmtExposure’, ‘BsmtFinType1’, ‘BsmtFinType2’においても欠損自体は「地下室が存在しない」という意味になるので、文字列の"None"で補完します。
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
combined_df[col] = combined_df[col].fillna('None')MasVnrTypeは、外壁レンガの種類に関するデータです。MasVnrTypeの欠損も「レンガを使っていない」という意味なので、"None"で補完します。
combined_df["MasVnrType"] = combined_df["MasVnrType"].fillna("None")欠損自体に意味を持っている数値(int, float型)データは0で補完する
まず地下室関連のデータのBsmtFinSF1, BsmtFinSF2, BsmtUnfSF, TotalBsmtSF, BsmtFullBath, BsmtHalfBath,はいずれも数値データとなっています。
NAとなっている箇所は地下室がないことを意味しているため、数値の0で補完します。こちらもまとめてfor文を用いて補完します。
for col in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
combined_df[col] = combined_df[col].fillna(0)MasVnrAreaのNaは、「レンガを使っていない(面積は0)」という意味なので、0で補完します。
combined_df["MasVnrArea"] = combined_df["MasVnrArea"].fillna(0)“GarageYrBlt”のNaは、「ガレージが無ければ建築年数が未記入」と考えられるので0で置き換えたいと思います。
combined_df["GarageYrBlt"] = combined_df["GarageYrBlt"].fillna(0)‘GarageArea’, ‘GarageCars’といったガレージに関するデータにおいても「ガレージがなければいずれも未記入」と考えられるので、0で補完したいと思います
for col in ('GarageArea', 'GarageCars'):
combined_df[col] = combined_df[col].fillna(0)欠損自体に意味を持たないobjectデータは最頻値で補完する
MSZoningという土地の種類を表すデータの欠損値を補完します。住宅において土地が存在しないということはありえません。つまり、MSZonigにおける欠損は意味を持たないことになります。
MSZoningのデータの種類と、それぞれどの程度データが割り当てられているのかを確認します。
combined_df['MSZoning'].value_counts()
# RL 2265
# RM 460
# FV 139
# RH 26
# C (all) 25
# Name: MSZoning, dtype: int64MSZoningのように種類を扱うデータの欠損値を補完する場合、他の変数との関係性が無ければ最頻値で補完するのが一般的です。
最頻値での補完はfillnaメソッドとmodeメソッドで行います。
combined_df['MSZoning'] = combined_df['MSZoning'].fillna(combined_df['MSZoning'].mode()[0])Functionalは、住宅の機能性ランクです。 どのような値が含まれているのかを確認してみます。
combined_df['Functional'].value_counts()
# Typ 2717
# Min2 70
# Min1 65
# Mod 35
# Maj1 19
# Maj2 9
# Sev 2
# Name: Functional, dtype: int64
データの殆どがTypとなっているので最頻値であるTypで補完します。先述のmodeメソッドで補完しても良いですが、以下のようにTypを直接指定してもOKです。
combined_df["Functional"] = combined_df["Functional"].fillna("Typ")‘Electrical’, ‘KitchenQual’, ‘Exterior1st’, ‘Exterior2nd’, ‘SaleType’においても、同様の考え方で最頻値で補完します。
combined_df['Electrical'] = combined_df['Electrical'].fillna(combined_df['Electrical'].mode()[0])
combined_df['KitchenQual'] = combined_df['KitchenQual'].fillna(combined_df['KitchenQual'].mode()[0])
combined_df['Exterior1st'] = combined_df['Exterior1st'].fillna(combined_df['Exterior1st'].mode()[0])
combined_df['Exterior2nd'] = combined_df['Exterior2nd'].fillna(combined_df['Exterior2nd'].mode()[0])
combined_df['SaleType'] = combined_df['SaleType'].fillna(combined_df['SaleType'].mode()[0])データとして意味をなさないものは削除する
Utilitiesというガス・電気の設備状況のデータを確認します。
combined_df['Utilities'].value_counts()
# AllPub 2916
# NoSeWa 1
# Name: Utilities, dtype: int64出力を確認すると、ほぼ全てがAllPubであることがわかります。
ほぼ全てAllPubということは、Utilitiesという特徴量は住宅価格に対して優劣をつけるような指標にならないため、列ごと削除してしまいます。
combined_df = combined_df.drop(['Utilities'], axis=1)【Python】欠損値の有無を確認する
欠損値の補完が完了したら、最終チェックとして欠損値の有無を確認しましょう。
欠損値の有無の確認はisnullメソッドとsumメソッドを使って確認します。
combined_df.isnull().sum().sort_values(ascending=False)
# SalePrice 1459
# MSSubClass 0
# GarageYrBlt 0
# GarageType 0
# FireplaceQu 0
# Fireplaces 0
# Functional 0
# TotRmsAbvGrd 0
# KitchenQual 0
# KitchenAbvGr 0
# BedroomAbvGr 0
# HalfBath 0
# FullBath 0
# BsmtHalfBath 0
# BsmtFullBath 0
# GrLivArea 0
# LowQualFinSF 0
# 2ndFlrSF 0
# 1stFlrSF 0
# GarageFinish 0
# GarageCars 0
# GarageArea 0
# PoolQC 0
# SaleCondition 0
# SaleType 0
# YrSold 0
# MoSold 0
# MiscVal 0
# MiscFeature 0
# Fence 0
# PoolArea 0
# GarageQual 0
# ScreenPorch 0
# 3SsnPorch 0
# EnclosedPorch 0
# OpenPorchSF 0
# WoodDeckSF 0
# PavedDrive 0
# GarageCond 0
# Electrical 0
# Id 0
# HeatingQC 0
# LandSlope 0
# OverallCond 0
# OverallQual 0
# HouseStyle 0
# BldgType 0
# Condition2 0
# Condition1 0
# Neighborhood 0
# LotConfig 0
# YearRemodAdd 0
# LandContour 0
# LotShape 0
# Alley 0
# Street 0
# LotArea 0
# LotFrontage 0
# MSZoning 0
# YearBuilt 0
# RoofStyle 0
# Heating 0
# BsmtCond 0
# TotalBsmtSF 0
# BsmtUnfSF 0
# BsmtFinSF2 0
# BsmtFinType2 0
# BsmtFinSF1 0
# BsmtFinType1 0
# BsmtExposure 0
# BsmtQual 0
# RoofMatl 0
# Foundation 0
# ExterCond 0
# ExterQual 0
# MasVnrArea 0
# MasVnrType 0
# Exterior2nd 0
# Exterior1st 0
# CentralAir 0
# dtype: int64こちらのように全て0となっていることを確認しましょう。
【Python】特徴量の変換処理
欠損値の補完が完了したら、特徴量の変換処理を行います。
特徴量の変換処理を行う理由は、文字列であるカテゴリ変数は、機械学習のモデルで解釈できないためです。
そのため、文字列データを数値データに変換する必要があります。
変換方法はいくつか存在しますが、ここでは以下の2つの変換手法を使用します。
- one-hot encoding
- label encoding
各々の特徴量の変換処理の詳細に関しては以下の記事を参照いただければと思います。

結論だけ述べると、2つの変換処理の使い分けの考え方は以下のとおりです。
特徴量の変換処理の使い分けの考え方
カテゴリ変数に「大小、良し悪し、高い低い」と言った尺度がある→label encoding
上記以外→one-hot encoding
label encodingを行うカテゴリデータの抽出
今回用意されているデータから、「品質が良い悪い」といった尺度を表すカテゴリデータを抽出します。
「品質が良い悪い」といった尺度を表すカテゴリデータとは、具体的にどのようなものかというと、BsmtFinType1というデータが該当します。
BsmtFinType1データの説明を見てみましょう。
以下のようにGCL(良い品質)、LwQ(低品質)という風に、尺度を表すカテゴリデータであることがわかります。
BsmtFinType1: Rating of basement finished area
GLQ Good Living Quarters
ALQ Average Living Quarters
BLQ Below Average Living Quarters
Rec Average Rec Room
LwQ Low Quality
Unf Unfinshed
NA No Basementこのように、データを1つ1つ確認しながら、label encodingの対象となるデータを抽出しましょう。
結果としては以下のカテゴリデータが、label encodingの対象になります。
('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')label encoding処理
label encoding処理は、sklearn.preprocessingのLabelEncoderで行います。
from sklearn.preprocessing import LabelEncoder
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
for c in cols:
lbl = LabelEncoder()
lbl.fit(list(combined_df[c].values))
combined_df[c] = lbl.transform(list(combined_df[c].values))label encodingが完了しているか以下のコードを実行して確認します。
combined_df[['FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold']].head(10)
# FireplaceQu BsmtQual BsmtCond GarageQual GarageCond ExterQual ExterCond HeatingQC PoolQC KitchenQual ... LandSlope LotShape PavedDrive Street Alley CentralAir MSSubClass OverallCond YrSold MoSold
# 0 3 2 4 5 5 2 4 0 3 2 ... 0 3 2 1 1 1 5 4 2 1
# 1 5 2 4 5 5 3 4 0 3 3 ... 0 3 2 1 1 1 0 7 1 4
# 2 5 2 4 5 5 2 4 0 3 2 ... 0 0 2 1 1 1 5 4 2 8
# 3 2 4 1 5 5 3 4 2 3 2 ... 0 0 2 1 1 1 6 4 0 1
# 4 5 2 4 5 5 2 4 0 3 2 ... 0 0 2 1 1 1 5 4 2 11
# 5 3 2 4 5 5 3 4 0 3 3 ... 0 0 2 1 1 1 4 4 3 9
# 6 2 0 4 5 5 2 4 0 3 2 ... 0 3 2 1 1 1 0 4 1 7
# 7 5 2 4 5 5 3 4 0 3 3 ... 0 0 2 1 1 1 5 5 3 10
# 8 5 4 4 1 5 3 4 2 3 3 ... 0 3 2 1 1 1 4 4 2 3
# 9 5 4 4 2 5 3 4 0 3 3 ... 0 3 2 1 1 1 15 5 2 0問題なくlabel encodingができていることが確認できました。
one-hot encodingを行うカテゴリデータの抽出
one-hot encodingを行うカテゴリーデータは、label encodingを行うデータ以外のデータとなります。
one-hotエンコーディングは、pandas.DataFrameを使用します。pandas.DataFrameによるone-hot encodingは、デフォルトでデータ型がobjectまたはcategoryとなっている列の全データをone-hot encoding処理する仕様となっています。一方、数値(int, float)やbool型の列は、デフォルトでone-hot encodingの変更対象外となります。
one-hot encodingの対象となるデータ以外のデータは、既にlabel encodingで数値またはbool型に変換済です。
そのため、one-hot encodingの対象としてcombined_dfをまるごと指定すれば良いことになります。
one-hot encoding処理
one-hot encoding処理を以下のコードで実行しましょう。
combined_df = pd.get_dummies(combined_df, drop_first=True)なお、drop_first=Trueオプションを付与すると、生成される列が1つ減ります。
「列が1つ減っても良いのか?」と思われると思いますが、one-hot encodingでは問題ありません。
例えば[りんご、みかん、スイカ]というデータがあったとしましょう。このデータをone-hot encodingした場合、りんごは[1, 0, 0]、みかんは[0, 1, 0]、スイカは[0, 0, 1]と表現されます。
では、1列削除した時、どのようになるかというと、りんごは[1, 0], みかんは[0, 1], スイカは[0, 0]となり、1列削除しても3つのカテゴリデータを表現できるのです。
すなわち、one-hot encodingはn個のデータがあった場合、n-1個のone-hot encodingをすれば、n個のカテゴリデータを表現できるという特性があるのです。
【Python】トレーニング用のデータとテスト用のデータに分割する
機械学習に提供するために、combined_dfをトレーニング用のデータとテスト用のデータに分割したいと思います。
train_df = combined_df[:len(train_df)]
test_df = combined_df[len(train_df):].drop(columns=['SalePrice'])
# X_trainには、SalePriceを除いたtrain_dfを代入。
X_train = train_df.drop("SalePrice", axis=1)
# y_trainには、SalePriceのみが入ったtrain_dfを代入。
y_train = train_df["SalePrice"]
# X_testには、test_dfを代入。
X_test = test_df
print(X_train.shape, y_train.shape, X_test.shape)
# (1460, 201) (1460,) (1459, 201)X_trainは、トレーニングデータのデータセット(正解ラベル以外)を格納します。
y_trainは、トレーニングデータの正解ラベルのみを格納します。
X_testは、テストデータのデータセット(正解ラベル以外)を格納します。
これで分割が完了しました。
機械学習モデルの選定と適用評価の準備
機械学習のアルゴリズムは50個以上存在し、解決する問題が何かによって最適なアルゴリズムは様々です。
一般的にアルゴリズムを選択する際の考え方は、Choosing the right estimator — scikit-learn 0.24.2 documentationに記載されているフローチャートがあります。
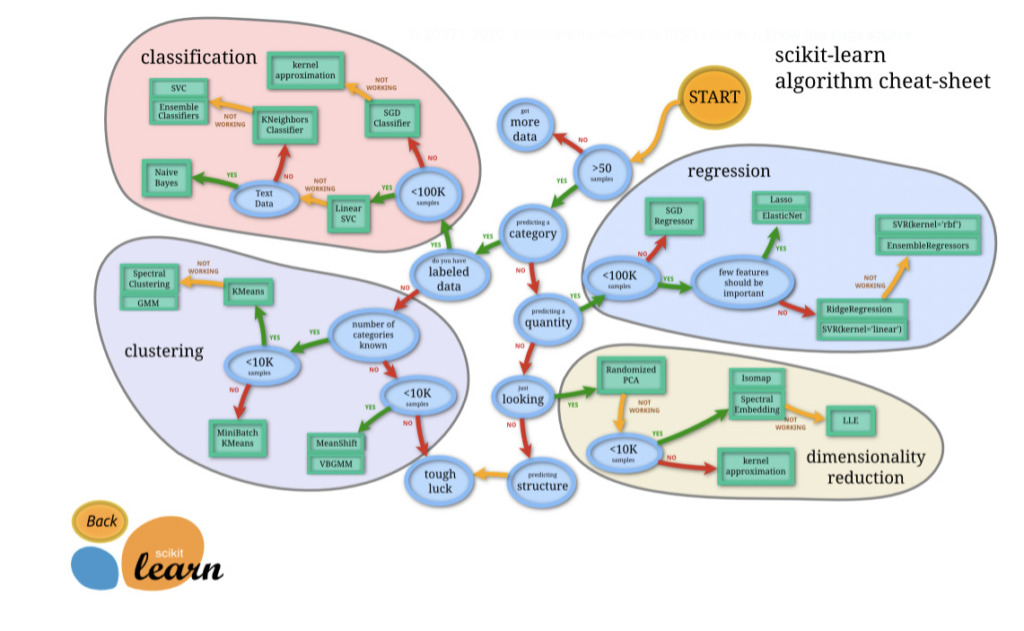
今回の問題は「回帰(regression)」の領域になります。
フローチャートを確認すると、データは10万件より小さいかを問われています。
今回のデータは、10万件よりも少ないため、「YES」となります。
続いて、「重要度の高い特徴量が含まれているか?」が問われています。
特徴量の重要度を定量的に評価することはできますが、ここは一旦「NO」を選択し、まずはRidgeRegressionsやEnsembleRegressionsを活用する方針で考えていきましょう。
というのも特徴量の重要度評価は、厳密に評価するのは難しく、場合によってはそれほど重要ではない特徴量が過大評価されるケースがあるためです。
最終的にどの機械学習を採用すればよいかは、KaggleのDiscussionや先人たちのコードを参照するのが手っ取り早いです。
本記事では、多くのKagglerが使用している「LightGBM」というモデルを活用したいと思います。
機械学習モデルの評価を関数化
まずKaggle House PricesのEvaluationを確認すると、「提出物はRoot-Mean-Squared-Rrror(RMSE)」で評価されることがわかります。
RMSEとは二乗平均平方誤差と言われ、$y_i$を観測値、$\hat{y}_i$を予測値とすると、定義式は以下のようになります。
$$
\mathrm{RMSE}=\sqrt{\frac{1}{n} \sum_{k=1}^{n}\left(y_{i}-\hat{y}_{i}\right)}
$$
評価はモデルを用いて学習を行うたびに実施するので、関数化しておきます。
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
def run_cv(model):
cv = KFold(n_splits=3, random_state=42, shuffle=True)
rmse_results = []
models = []
for trn_index, val_index in cv.split(X_train):
X_trn, X_val = X_train.loc[trn_index], X_train.loc[val_index]
y_trn, y_val = y_train[trn_index], y_train[val_index]
# モデルの学習
model.fit(X_trn, y_trn)
pred = model.predict(X_val)
# モデルの精度を算出
rmse = np.sqrt(mean_squared_error(y_val, pred))
print("RMSE:", rmse)
rmse_results.append(rmse)
models.append(model)
print(rmse_results)
print("Average:", np.mean(rmse_results))
return modelsこちらのコードは、scikit-learnのモデルのインスタンスを渡すと、k=3のKFoldと呼ばれるモデル評価手法で、平均精度を算出する関数です。
モデルを評価する方法はKFoldの他に様々な種類がありますが、本記事では割愛します。
LightGBMによる学習と予測
ここまででデータの準備、モデルの選定、モデルの評価方法の明確化が完了しました。
ここからは、モデルの選定パートで適用するモデルとして選定した「LightGBM」の実装を進めます。
「LightGBMとはなにか?」については長くなるので本記事では割愛しますが、簡単に言うと、”木構造を用いた勾配ブースティングのフレームワーク”です。
主な特徴は以下のとおりです。
- トレーニング速度が従来のモデルに比べて速い
- メモリの使用量が小さい
- 精度は従来のモデルと同等
- 並列・分散処理、GPU学習をサポートしている
- 大規模データを処理できる
詳しく知りたい方は、公式ドキュメントを参照いただければと思います。
LightGBMを実装していきます。なお、このような実装する上でのコード作成は、Kaggle上に多くのコードが公開されているので、基本的には使えそうなコードを見つけて拝借するのが効率的です。
import lightgbm as lgb
lgb_params = {
"objective":"regression",
"metric": "rmse"
}
cv = KFold(n_splits=3, random_state=42, shuffle=True)
rmse_results = []
lgbm_models = []
# テストデータに対する予測結果を格納するための空の配列
test_preds = np.zeros(len(X_test))
for trn_index, val_index in cv.split(X_train, y_train):
X_trn, X_val = X_train.loc[trn_index], X_train.loc[val_index]
y_trn, y_val = y_train[trn_index], y_train[val_index]
train_lgb = lgb.Dataset(X_trn, y_trn)
validation_lgb = lgb.Dataset(X_val, y_val)
model = lgb.train(
lgb_params, train_lgb,
num_boost_round=1000, valid_sets=[train_lgb, validation_lgb],
verbose_eval=10,
early_stopping_rounds=100
)
pred = model.predict(X_val)
rmse = np.sqrt(mean_squared_error(y_val, pred))
print("RMSE:", rmse)
rmse_results.append(rmse)
lgbm_models.append(model)
test_preds += model.predict(X_test) / cv.n_splits
print(rmse_results)
print("Average:", np.mean(rmse_results))簡単にコードの説明をします。
まず、KFoldで、用意したトレーニングデータを3分割(n_splits=3)し、そのうちの1つをテストデータ、残りの2つを学習データに分けています。
また、テストデータに対して過度に精度の高いモデルになることを防ぐために、検証用のバリデーションデータを用意しています。
num_boost_roundは、ブースティングの反復回数、valid_setsにはバリデーションデータをリストで指定します。このあたりは、公式ドキュメントに従ってパラメータを設定します。
verbose_evalは、学習過程の表示するサイクルです。ここではひとまず10を設定しています。
early_stopping_roundは、過学習を回避するための早期終了処理です。(参考: https://rin-effort.com/2019/12/29/machine-learning-6/)
実行結果としては以下の通りとなります。
[LightGBM] [Warning] Find whitespaces in feature_names, replace with underlines
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.001846 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 3223
[LightGBM] [Info] Number of data points in the train set: 973, number of used features: 123
[LightGBM] [Warning] Find whitespaces in feature_names, replace with underlines
[LightGBM] [Info] Start training from score 181111.430627
Training until validation scores don't improve for 100 rounds
[10] training's rmse: 36931.2 valid_1's rmse: 46543.6
[20] training's rmse: 24638.1 valid_1's rmse: 35594.5
[30] training's rmse: 19880.1 valid_1's rmse: 32265.3
[40] training's rmse: 16898.3 valid_1's rmse: 31407.6
[50] training's rmse: 15189.4 valid_1's rmse: 31262.1
[60] training's rmse: 13853 valid_1's rmse: 31224.8
[70] training's rmse: 12768.9 valid_1's rmse: 31299.5
[80] training's rmse: 11852.2 valid_1's rmse: 31300.7
[90] training's rmse: 11057.3 valid_1's rmse: 31302.6
[100] training's rmse: 10255.7 valid_1's rmse: 31375.9
[110] training's rmse: 9636.43 valid_1's rmse: 31516.6
[120] training's rmse: 9013.41 valid_1's rmse: 31623.3
[130] training's rmse: 8496.04 valid_1's rmse: 31715.2
[140] training's rmse: 7974.86 valid_1's rmse: 31752.5
[150] training's rmse: 7560.89 valid_1's rmse: 31885.1
Early stopping, best iteration is:
[53] training's rmse: 14763.5 valid_1's rmse: 31157.4
RMSE: 31157.372984878297
[LightGBM] [Warning] Find whitespaces in feature_names, replace with underlines
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.002099 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 3193
[LightGBM] [Info] Number of data points in the train set: 973, number of used features: 124
[LightGBM] [Warning] Find whitespaces in feature_names, replace with underlines
[LightGBM] [Info] Start training from score 180286.591984
Training until validation scores don't improve for 100 rounds
[10] training's rmse: 38017.3 valid_1's rmse: 42152
[20] training's rmse: 24307 valid_1's rmse: 34552.4
[30] training's rmse: 19311.1 valid_1's rmse: 33530.4
[40] training's rmse: 16951.4 valid_1's rmse: 33711.4
[50] training's rmse: 15374.5 valid_1's rmse: 33820.4
[60] training's rmse: 14127.3 valid_1's rmse: 34028.5
[70] training's rmse: 13089.4 valid_1's rmse: 34385.8
[80] training's rmse: 12134.2 valid_1's rmse: 34784.3
[90] training's rmse: 11400.2 valid_1's rmse: 35066.3
[100] training's rmse: 10628.2 valid_1's rmse: 35538.9
[110] training's rmse: 9966.81 valid_1's rmse: 35736.9
[120] training's rmse: 9371.28 valid_1's rmse: 36130.1
[130] training's rmse: 8820.18 valid_1's rmse: 36333.6
Early stopping, best iteration is:
[34] training's rmse: 18206.6 valid_1's rmse: 33458.3
RMSE: 33458.28014607101
[LightGBM] [Warning] Find whitespaces in feature_names, replace with underlines
[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.002133 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 3213
[LightGBM] [Info] Number of data points in the train set: 974, number of used features: 123
[LightGBM] [Warning] Find whitespaces in feature_names, replace with underlines
[LightGBM] [Info] Start training from score 181365.108830
Training until validation scores don't improve for 100 rounds
[10] training's rmse: 40492.3 valid_1's rmse: 38181.9
[20] training's rmse: 27723.1 valid_1's rmse: 28352.2
[30] training's rmse: 23182.4 valid_1's rmse: 25542.8
[40] training's rmse: 20680.9 valid_1's rmse: 24459.4
[50] training's rmse: 18741.8 valid_1's rmse: 24073.3
[60] training's rmse: 17223.6 valid_1's rmse: 24106.5
[70] training's rmse: 15939.1 valid_1's rmse: 24275
[80] training's rmse: 14924.8 valid_1's rmse: 24375.9
[90] training's rmse: 13974.2 valid_1's rmse: 24383.5
[100] training's rmse: 12959.1 valid_1's rmse: 24450.3
[110] training's rmse: 12185.3 valid_1's rmse: 24518.3
[120] training's rmse: 11415.2 valid_1's rmse: 24633.4
[130] training's rmse: 10733.9 valid_1's rmse: 24713.2
[140] training's rmse: 10067.9 valid_1's rmse: 24867.3
[150] training's rmse: 9508.78 valid_1's rmse: 24917.9
Early stopping, best iteration is:
[56] training's rmse: 17852.2 valid_1's rmse: 24023.8
RMSE: 24023.785616027122
[31157.372984878297, 33458.28014607101, 24023.785616027122]
Average: 29546.47958232548テストデータに対する予測結果をKaggleに提出
LightGBMを用いてテストデータに対する予測結果をKaggleに提出していきます。
# サンプル提出ファイルの予測値列の値を変更
submission = pd.read_csv('../input/house-prices-advanced-regression-techniques/sample_submission.csv')
submission['SalePrice'] = test_preds
# 提出ファイルを出力
submission.to_csv("submission.csv", index=False)コードの実行が完了したら、画面右上の「Save Version」を押しましょう。
ポップアップが現れるので、そのまま「Save」をクリックしましょう。
「Save」を押すと、画面左下にコードの全実行処理が実行中の表示が現れます。
“Successful”という表記に変わったら成功です。
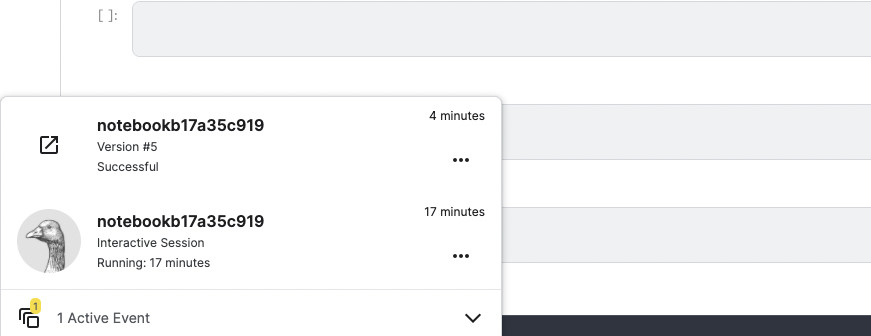
初めて提出する場合、画面右上の「Save version」の表記が「Save version | 1」という風になると思います。この「1」という数字の部分を押すと、「Version Histry」というのが現れます。そして提出するファイルを選択し、「Submmit to Competition」を押しましょう。
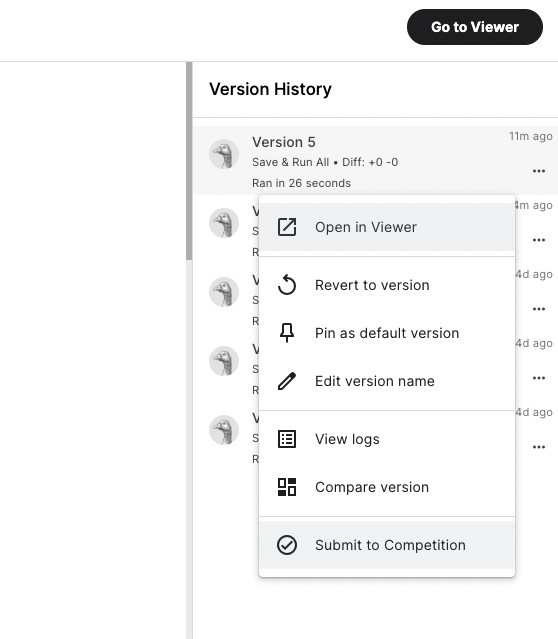
すると、ポップアップが表示されますので、「Submit」を押しましょう。
“Submit to Competition”という表示が現れます。「View My Submissions」を押しましょう。
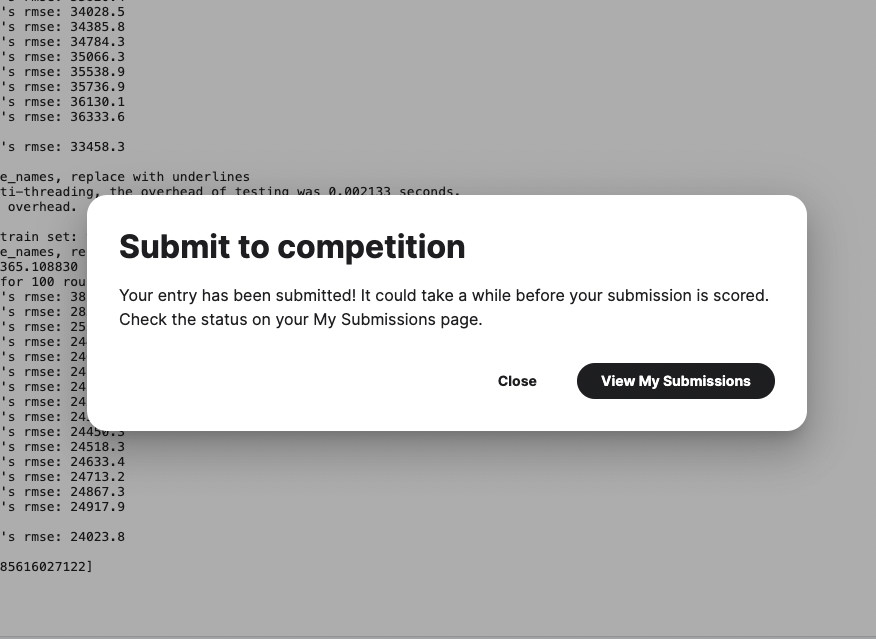
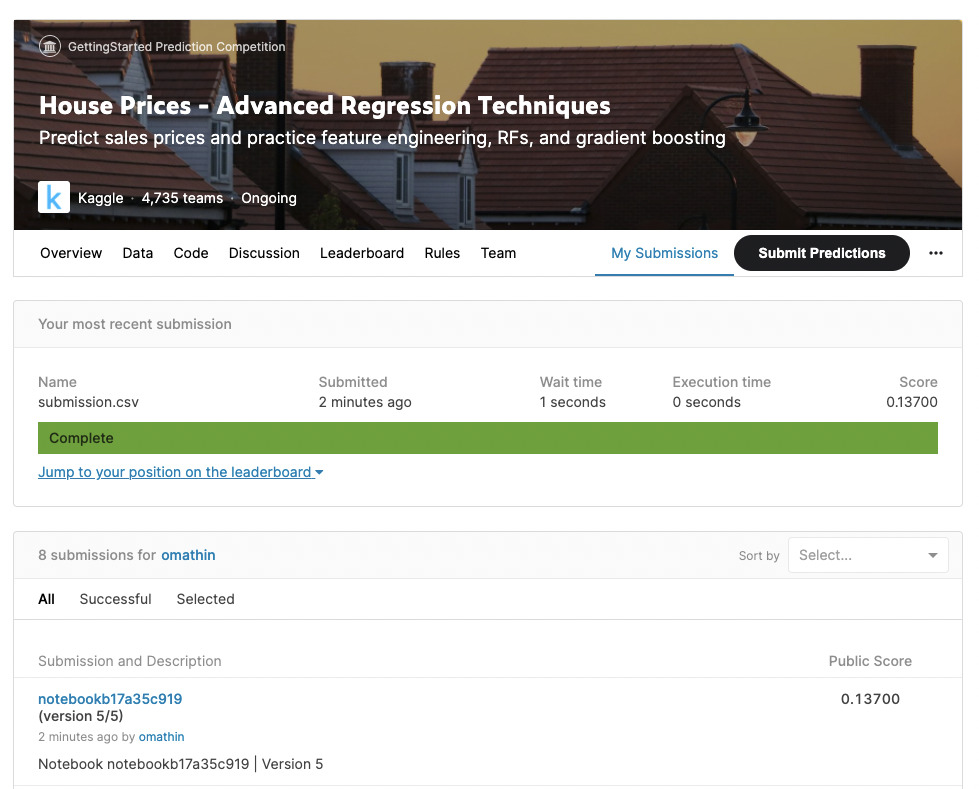
すると、”Public Score”という箇所に、点数が表示されます。値が小さければ小さいほど良い予測ができていることになります。ここでは、”0.13700″となっています。
ランキングを見たい場合は、「Leaderboard」というタブを選択しましょう。下にスクロールすると、全体で何番目くらいなのかを確認できます。

まとめ:Kaggleに入門することができました
本記事では、データの確認、欠損値の補完、特徴量の変換処理、モデルの選定および実装と評価、そしてKaggleへの提出まで行いました。
ここで紹介した流れは、データサイエンティスト業務の軸となる手順なので、本記事を元に知見を深めていただければと思います。
なお、今回実施した住宅価格の予測精度は、まだまだ改善させることが可能です。
具体的には「特徴量を新たに追加」したり、「モデル自体の改善」を行えば、精度をあげることができます。
Kaggleには、モデルの改善方法の参考になるコードがオープンになっています。そちらを参照しながら試してみると良いでしょう。
もしデータサイエンティストに興味を持たれた方は、キカガクやAidemyといったAI・データサイエンスに特化したスクールで学ぶのが効率的です。
特に私が実際に受講したAidemyのデータ分析コースはおすすめです。なぜなら、Kaggleを扱った講座が含まれており、実践的だからです。
レビュー記事も書いているので、よかったら見ていってください。
>> Aidemy(アイデミー)の評判・口コミをAidemy受講者が解説!

「10万円とかプログラミングスクールにお金かけられない」という人は、Udemyも良いです。
Python初学者におすすめな講座も紹介しているので、こちらもよかったら見ていってくださいね。
>> 【Udemy】Python初心者向けおすすめ講座8選ぶ【決定版】

キカガクは、無料でオンライン相談会も開催しているので、気軽に参加してみましょう。
買い切り型のプログラミング教材については、【厳選】オンラインプログラミングスクールおすすめ6選!【買い切り型が最強です】にまとめているので、あわせてご確認ください。


コメント